Introduction
The purpose of this project is to create a Scheme interpreter using C language and Mega32 microprocessor. Using limited resource and memory in the microprocessor, the interpreter should function and work for basic Scheme commands. The main target of the project is to use the memory of the microprocessor as fully as possible to make the interpreter perform major functions. Also, there will be limitation of the number of loops and memory that the interpreter could face memory shortage. In order to relieve the memory restraint to certain level, both FLASH and EEPROM have to be used.
High Level Design
– Rationale –
The idea of the project started from the pseudo code of Scheme interpreter using C++. For the final project of the microcontroller class, our group hoped to find a project that could maximize the use of memory and microcontroller. Also, from the project, we hope to experience intense C coding experiment and understanding of new language, Scheme. Creating a Scheme interpreter using C, running in Atmel Mega32 microcontroller chip challenged the group to write a extensive and complicated C code that could run and interpreted by Code Vision AVR and microcontroller while understanding the structure and functionality of Scheme language. Compared to most of the group where they would have hardware complexity and difficulty, even though we don’t have something tangible hardware other than Mega32 chip and STK500 board, this project will have software complexity and challenges.
It would be extremely hard to create an interpreter without a pseudo code, but with experience in the previous class, the pseudo code enabled our group to understand and finish the project. Thus, we have to give credit to the professor Kyu-Seok Shim (Seoul National University) for providing pseudo code and lecture notes on Scheme language and interpreter.
– High Level Overview –
The high level design of this project is mainly the interpreter code and tokenizer. As UART and computer keyboard inputs are used, part of the code is to read and write the data in and out. The serial communication between PC and MCU has been used and the code has been obtained from course material (provided by Prof. Bruce Land) and modified to satisfy the need of our project. The code for interpreter has been started from the scratch with the reference of pseudo code.
The first and probably one of the most important part of the project is to create a tokenizer that could identify the input and create a tokenized version of input so that it could be used by interpreting step. As interpretation total rely on the output of the tokenizer, it is extremely important to have a correct tokenizer and the function that could read and output next token. Detail structure and explanation of how tokenizer works will be discussed in the software design section.
The interpreter can be divided into many sub-parts: Preprocessing, Make-hash, Build node tree (Read) and Evaluation. Each step of interpretation will be discussed again in software section.
– Trade Off –
As there were many different software problems, errors, and issues arose while creating an interpreter, we spend all our effort and time to make the interpreter to function correctly. Thus, as trade-off, it was impossible for us to spare time to create possible hardware related to the project, such as external memory, LCD and keypads.
– Standards, Copyrights & Patents –
For Scheme language, there are official IEEE standard and and a de facto standard called the Revisedn Report on the Algorithmic Language Scheme, abbreviated as RnRS, where n is the number of revision. R5RS standard is the most widely implemented and R6RS has been ratified on August 28th, 2007 for next major revision. As regarding the intellectual property, the e-mail has been sent to get consent for using course material (lecture note, peudo code) to professor at Seoul National University.
Hardware Design
The hardware design of this project is simple. STK500 board with Atmel Mega32 microcontroller unit has been used with serial cable connecting PC and the STK500 board. In order to enable the UART, the jumper has to be connecting PORT D pin 0 and pin 1 to the RS232-spare header. Also set up the termial to 9600 baud, no parity, one stop bit, and no flow control. There is no other hardware requirement to run the interpreter.
Software Design
This project is very programming-intense that our group spent most of our time programming and fixing the code. The trickiest part was fitting the data structure into the limited memory and preprocessing the command and creating some functions such as GetNextToken. Also, the pseudo code provided by Prof. Kyu-Seok Shim in Seoul National University has been an important source for our interpreter.
– Data Structure –
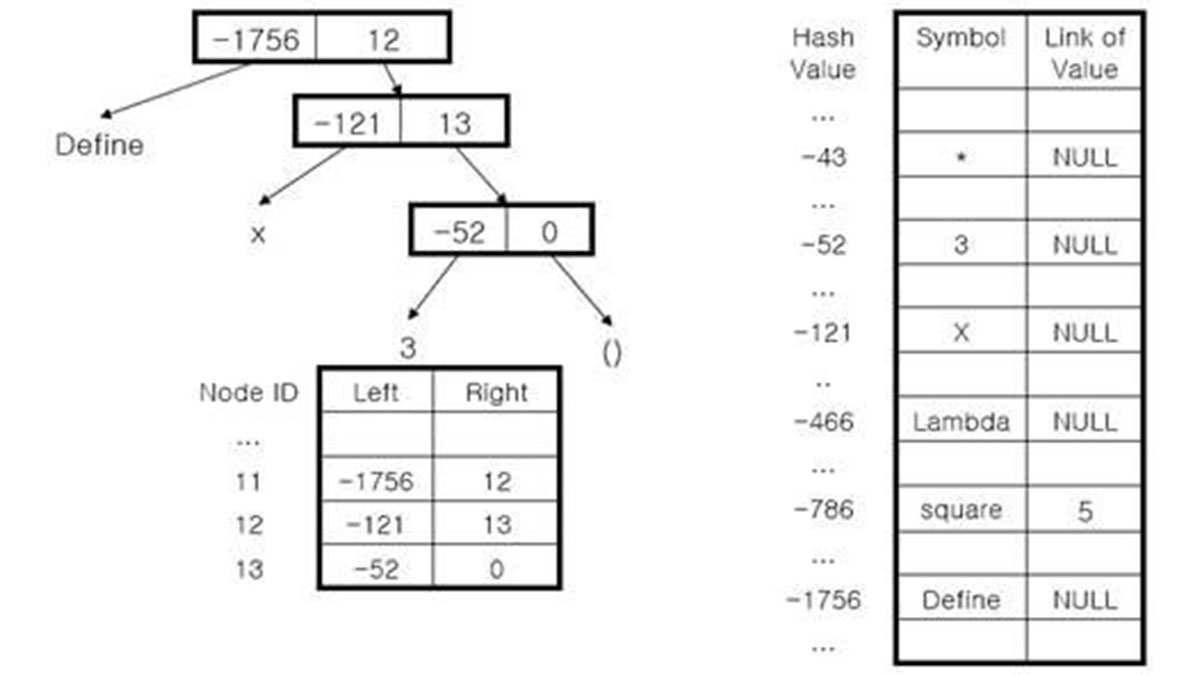
There are two main data structures which are the node tree and the hash table.
Initially, the interpreter allocates a large number of nodes consisting three pointers, left child, right child and next. Left child and right child are for pointing other nodes or symbols, and next is for the nodes waiting at the free list. After receiving input commands, node trees would be constructed to store arrays and user defined functions. Unused nodes would wait for further commands at the free list.
When a new command comes, the interpreter stores new symbols into the hash table. The hash table is efficient in that the access time is much shorter than the regular table with search algorithms. The hash function would be specified carefully to minimize collisions. To distinguish nodes from symbols, we would use positive indices for node ids, and negative indices for the hash table. Each entry of the hash table has its symbol and a link of value. The variables would be linked to the index of the hash table or the root node of the array, and user defined functions would be linked to the root node of the node tree where the function has defined.
– Limited Memory –
In order to perform as an interpreter we need to have a hash table and node tree that could store the value and also evaluate. However, there is limited memory within the Mega32 chip (2048 bytes for SRAM). Because of memory shortage, the program frequently showed errors and did not function correctly. Also, there could be limited number of lines and complexity of the function that could be used due to memory shortage. Specifically, the data stack size was too small, so there was the limit to the number of recursive function calls. In order to release such restriction on memory, we put the entire node tree and the hash table into EEPROM which has 1024 bytes of memory. This enabled us to increase the data stack size to the reasonable size that the program works for basic functionalities.
– Tokenizer –
The tokenizer is the most basic and important part of the project. It divides the command into tokens, and returns the next token every time it is called. Tokens could be divided by a space, parenthesis, and a quotation mark. The tokenizer searches the command for those three characters, and returns a string between two of them. Parenthesis and a quotation mark are also tokens, so it returns them as a token, too.
– Preprocessing –
The first step of creating an interpreter is to get the input string and preprocess it. We need to make sure to differentiate different inputs and put it into a readable and interpretable form. In order to enable serial communication, the code used in Lab 3 has been used. We modified the code to meet the need of our project. This source code for serial communication has been provided by Prof. Bruce Land. After receiving the command, the interpreter starts preprocessing. It converts the command into the standard format. The standard format includes using the quote function instead of a quotation mark for an array and using the lambda format for the user defined functions. Also, after preprocessing, the command would have only one space between every two tokens.
For example, if the command is (define (square x) (* x x)), after preprocessing it would be ( define square ( lambda ( x ) ( * x x ) ) ).
– Make Hash –
This function reads the command after preprocessing, and insert new symbols to the hash table.
– Node Tree Construction –
It is done by the function Read. The scheme command is relatively simpler than other programming languages. The basic form is (func arg1 arg2 … argN) where each argument could be the other command. The left child of the node points to each token, and the right child of the node points to the next node.
Parts List:
|
Part |
Quantity |
Price |
| STK500 Board |
1 |
$15 |
| Atmel Mega32 |
1 |
$8 |
| STK500 Power Supply |
1 |
Free |
| USB to Serial Cable |
1 |
Free |
| Serial Cable |
1 |
Free |
| 2 pin Flat Jumper Cable |
1 |
$1 |
|
Total |
|
$24 |
For more detail: SCHEME INTERPRETER USING ATMEGA32