Summary of Embedded Controllers Using C and Arduino / 2E
This course introduces C programming for embedded systems, assuming prior knowledge of languages like Python. It covers memory organization, data types, and functions, transitioning from desktop compilers to Arduino Uno boards. The curriculum emphasizes C's efficiency, low-level hardware control, and structured nature compared to C++ or assembly, preparing learners for independent embedded development projects.
Parts used in the Arduino Embedded Programming Course:
- Arduino Uno board
- USB host cable
- Small wall-mounted power adapter
- Desktop C compiler (e.g., Visual C/C++, GCC, Pelles C)
- C programming textbook (e.g., "Programming in C" by Kochan)
1. Course Introduction
1.1 Overview
This course serves as an introduction to the C programming language with a specific emphasis on embedded programming. It assumes that you have prior experience with a high-level language such as Python, BASIC, FORTRAN, or Pascal. Given the intricacies of embedded systems, we commence our journey by exploring the language’s structure and fundamental examples within a conventional desktop environment. After establishing a solid foundation in syntax, structure, and the development process, we transition to an embedded system, specifically the Arduino-based development platform.

This course is thoughtfully designed to enable substantial independent work from the comfort of your home, and it can be done with minimal expense if you so choose (although it’s worth noting that programming these little devices can be quite addictive). In addition to the course materials and the accompanying lab manual, you’ll require an Arduino Uno board (approximately $25) and a USB host cable. It may also be beneficial to have a small wall-mounted power adapter. While there is an abundance of free C programming resources available online, if you prefer printed books with in-depth content, you might consider purchasing one of the many C programming texts. Two recommended titles are “Programming in C” by Kochan and the one authored by Deitel & Deitel, “C-How to Program.” When selecting a book, ensure that it focuses on C rather than C++. You’ll also need a desktop C compiler, and nearly any compiler will suffice, such as Visual C/C++, Borland, CodeWarrior, or even GCC. There are a couple of decent freeware compilers available online, such as Pelles C and Miracle C.
1.2 Frequently Asked Questions
Why learn C language programming?
C stands as one of the most prevalent programming languages in use today. This popularity is just one of several compelling reasons to consider it. There are, however, additional factors to take into account:
– C is a contemporary, structured language that has undergone standardization (ANSI).
– Its modular nature enables code reusability.
– C enjoys broad support, facilitating the use of source code across various platforms with simple recompilation for the new target.
– Its widespread adoption has led to a plethora of third-party add-ons, including libraries and modules, to enhance the language’s capabilities.
– C incorporates type checking, which aids in error detection.
– It offers remarkable power, allowing developers to work at a low level, close to the hardware.
– In general, C produces highly efficient code with minimal space usage and rapid execution.
How does C differ from C++?
C++ is essentially an extension of C, with C preceding its development. Interestingly, the name “C++” carries a humorous programmer’s connotation, as “++” signifies the increment operator in C. Thus, “C++” can be interpreted as “increment C” or even “give me the next C.” C++ encompasses all the functionality of C and adds numerous advanced features. However, these added features come at a cost, and embedded applications typically cannot afford the associated overhead. As a result, while C++ is commonly used in desktop development, C remains the preferred choice for most embedded systems. Desktop development environments are often referred to as “C/C++ systems” since they support both languages, while embedded development systems may strictly adhere to C or even a modified version of it, as in our case.
Where can I buy an Arduino development board?
You can find the Arduino Uno board at various retailers, including Digi-Key, Mouser, Parts Express, and other outlets. It’s a good idea to compare prices and options before making a purchase.
What’s the difference between desktop PC development and embedded programming?
Desktop development is centered around creating software applications tailored for use on desktop computers. This category encompasses a wide range of applications, such as word processors, graphic tools, games, CAD programs, and more. These are typically what most people associate with the term “computer.”
In contrast, embedded programming is focused on the multitude of inconspicuous applications that exist in our daily lives. These applications often go unnoticed but are integral to the functioning of various devices, including microwave ovens, automobile engine management systems, cell phones, and many others. When considering the sheer number of units in use, embedded applications far surpass desktop applications. While you may have one or a few personal computers at home, it’s likely that you interact with numerous embedded applications on a daily basis.
Embedded microcontrollers, while less powerful, are also significantly more cost-effective than their PC counterparts. The distinct programming techniques required for embedded systems are a crucial aspect of this course, and we will devote substantial time to exploring these techniques.
How does C compare with Python?
If, like numerous students enrolled in this course, you come from a background in the Python programming language, you might initially find certain aspects of C to be a bit unfamiliar. Some parts of C may appear more complex at first glance. However, there’s no need to be concerned. In reality, the core of the C language is quite straightforward. Python tends to shield many details from the programmer, while C does not. Initially, this might make things seem more intricate, especially in simple programs. However, when dealing with more intricate tasks, C often simplifies the matter significantly. Many forms of data manipulation and hardware control are notably more direct and efficient in C compared to other programming languages. One practical aspect to consider is that C is a compiled language, whereas most versions of Python are primarily interpreted. This means there’s an additional step in the development process, but the resulting compiled program is considerably more efficient. We will delve into the reasons for this distinction a bit later in the course.
How does C compare with assembly language?
Traditionally, assembly language was the preferred choice when optimizing code size and execution speed were paramount considerations. In the past, nearly all embedded programming was accomplished using assembly. However, as microcontrollers have become more powerful and C compilers have advanced, the balance has shifted. The drawbacks of assembly language have become increasingly prominent. Assembly is tightly tied to a specific processor, lacks structure, is not standardized, and is not particularly readable or writable. On the other hand, C now provides performance capabilities similar to assembly while incorporating all the benefits of a contemporary structured language.
2. C Memory Organization
2.1 Introduction
When working with C programming, having some understanding of the inner workings of basic computer systems can be quite advantageous. Since C operates at a relatively low level, it becomes easier to comprehend the execution of certain operations and the adoption of preferred coding techniques.
To begin, let’s focus on a specific area by limiting our exploration to relatively simple computer systems, such as those commonly found in embedded applications. These systems typically feature a basic processor and solid-state memory, excluding considerations related to disk drives, monitors, and similar components. Detailed information regarding controller architecture, memory hardware, and internal input-output circuitry will be discussed in later chapters.
2.2 Guts 101
A basic computing system comprises a central processing unit (CPU), microprocessor, or microcontroller as its control device. While there exist nuanced distinctions among these terms, we need not delve deeply into those intricacies for our current purpose. Microcontrollers typically exhibit lower processing speed compared to standard microprocessors but compensate by offering a range of on-chip input/output ports and hardware functions, like analog-to-digital or digital-to-analog converters, which are generally absent in typical microprocessors. To maintain simplicity, we’ll use the term “processor” in a generic sense.
Microprocessors typically require external memory, such as RAM chips, for their operation. In contrast, microcontrollers often incorporate sufficient on-board memory to obviate the need for external memory. It’s important to note, however, that we’re not dealing with large memory quantities in the order of megabytes. A microcontroller might possess only a few hundred bytes of memory, which can suffice for uncomplicated applications. Keep in mind that a byte of memory comprises eight bits, with each bit representing a binary 1/0, high/low, yes/no, or true/false value pair.
For a processor to perform operations on data stored in memory, the data must first be copied into one of the processor’s registers (which may number in the dozens). Mathematical or logical operations can only take place within these registers. For example, if you wish to increment a variable by one, the variable’s value must initially be copied into a register. The addition is carried out on the register’s contents, producing the result. This result is then copied back to the original memory location of the variable. Although this may seem somewhat circuitous initially, rest assured that the C language compiler will handle most of these intricacies for you.
2.3 Memory Maps
Every byte of memory within a computer system is assigned a unique address. This assignment is imperative because, without an address, the processor lacks the means to pinpoint a particular memory location. Typically, memory addressing commences at 0 and progresses incrementally, although in certain systems, some addresses might be designated as “special” or “reserved.” In such cases, a specific address may not correspond to standard memory but instead may be associated with a particular input/output port for external communication. Frequently, creating a memory map proves beneficial. This map essentially consists of an extensive array of memory slots. Some individuals depict them with the lowest (initial) address at the top, while others depict them with the lowest address at the bottom.
Here’s an example with just six bytes of memory:
Each memory address or slot is a location designated for storing a single byte. Remembering specific addresses would be a cumbersome task, but thankfully, the C compiler takes care of this for us. For instance, if we declare a character variable named “X,” it might be located at address 2. When we need to access the value of “X,” we don’t have to explicitly state, “retrieve the value at address 2.” Instead, we simply say, “retrieve the value of X,” and the compiler generates the necessary code to resolve this to the correct address (in this case, 2). This abstraction significantly reduces our mental workload. As many variables require more than one byte, it becomes necessary to combine addresses to store a single value.
For instance, if we choose a “short int,” which occupies two bytes, and it begins at address 4, it will also use address 5. When we access this variable, the compiler automatically generates code to utilize both addresses because it “understands” that we are working with a short int. In our modest six-byte memory map, we could accommodate various combinations, such as 6 characters, 3 short ints, 1 long int with 1 short int, 1 long int with 2 characters, or similar configurations. However, it cannot store a “double” as it requires 8 bytes. Similarly, it cannot accommodate an array of 4 or more short ints (for details on numeric data types, refer to Chapter Three).
Arrays hold a particular significance as they must be contiguous in memory. For instance, if a system has 1000 bytes of memory and a char array with 200 elements is declared, starting at address 500, then all slots from address 500 through 699 are assigned to the array. Arrays cannot be scattered across memory with bits here and there; they must be contiguous. This requirement arises from the method in which arrays are indexed and accessed, as we will explore in later sections.
2.4 Stacks
Numerous programs require temporary storage for specific variables, which means these variables are only used for a limited duration before they are no longer necessary. Allocating permanent space for such variables would be inefficient. Instead, many systems utilize a stack for this purpose. Typically, an application is divided into two main sections: a code section and a data section. The data section accommodates “permanent” or global data. As these sections do not occupy the entire memory map, the remaining memory is often designated for temporary storage through a stack. The stack begins at the opposite end of the memory map and expands in the direction of the code and data sections. This type of stack is referred to as a First-In-Last-Out (FILO) stack, functioning akin to a stack of trays in a cafeteria. The first tray placed on the stack will be the last one removed, and vice versa.
When temporary variables are required, this memory area is employed. As more items are needed, more memory is allocated. When our code exits from a function, the temporary (auto) variables declared within that function are no longer required, leading to a reduction in the stack’s size. If we make numerous function calls with a multitude of declared variables, it is conceivable for the stack to exceed the boundaries of the code and data sections of our program. In such a scenario, the system becomes corrupted, jeopardizing the program’s proper execution and functionality.
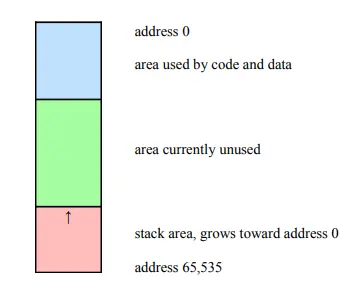
Above is an illustration of a memory map for a system that possesses 64 kilobytes of memory, denoted as “k” where k is equal to 1024 or 2^10. This depiction focuses on the general regions rather than individual memory slots.
It’s important to recognize that in certain systems, code and data coexist within a common area, as demonstrated in the Von Neumann architecture. In contrast, some systems physically segregate code and data (Harvard architecture). Whether they are separated or not, the fundamental principles remain the same. So, why might we choose to partition these two areas, each accessible through its own memory bus? The answer is straightforward: dividing the code and data enables the processor to retrieve the next instruction (code) using a memory bus that is physically distinct from the data bus it is currently employing. If a single memory bus were shared for both code and data, it would necessitate special timing to synchronize this process since only one entity can utilize the bus at any given moment. Having two distinct memory buses accelerates execution times.
3. C Language Basics
3.1 Introduction
C is known for its conciseness and is tailored for experienced programmers who need to accomplish a lot with minimal code in a short time. In contrast to languages like BASIC or Python, C is a compiled language. This means that after you’ve written a program, it must be processed by a compiler, which translates your C language instructions into machine code that the microprocessor or microcontroller can execute. While this introduces an extra step, it results in a more efficient program compared to an interpreter. An interpreter translates your code into machine language on the fly, essentially one line at a time, leading to slower execution. Additionally, for your program to run on another machine, that machine must also have an interpreter. You can think of a compiler as performing the entire translation in one go, as opposed to line by line.
In contrast to many other languages, C is not structured around lines but follows a free-flow style. A program can be broken down into three fundamental components: variables, statements, and functions. Variables serve as storage spaces for data, as in any other programming language. They can represent integers, floating-point (real) numbers, or other data types. Statements encompass operations on variables and assignments (e.g., setting x to 5 times y), tests (e.g., checking if x is greater than 10), and similar operations. Functions comprise statements and may also call other functions.
Variable Naming, Types and Declaration
Variable naming adheres to a relatively straightforward set of rules. Variable names are composed of a combination of letters, numerals, and underscores. Both uppercase and lowercase letters can be used interchangeably, and the typical maximum length for a variable name is 31 characters. However, the actual limit may vary depending on the specific C compiler being employed. It’s important to note that a variable name cannot be a reserved (key) word, and it must not include special characters like periods, semicolons, commas, asterisks, hyphens, and so on. Therefore, permissible variable names can include examples such as “x,” “volts,” “resistor7,” or even “I_Wanna_Go_Home_Now.”
C supports a variety of variable types, including floating-point or real numbers, available in two primary variants: “float,” which is a 32-bit number, and “double,” offering higher precision with 64 bits. Additionally, there are several integer types, including “char” (8 bits), “short int” (16 bits), and “long int” (32 bits). The “char” type, with its 8 bits, can represent 256 different values, making it suitable for single ASCII characters, which is how it got its name. Similarly, “short int” (or simply “short”) can accommodate 65,536 values, as it can hold 2 to the power of 16 combinations. Both “char” and “int” can be either signed or unsigned, with the default being signed, allowing for negative values.
Moreover, there is a basic “int” type, which can vary in size, being either 16 or 32 bits, depending on what is most efficient for the compiler. As a precaution, it is advisable not to use a plain “int” when the value might require more than 16 bits.
Occasionally, you may encounter special data types like “double long integers” (sometimes referred to as “long longs”), which occupy 8 bytes, as well as “80-bit extended precision floats” as defined by the IEEE.
Here is a table to summarize the sizes and ranges of variables:
| Variable Type | Bytes Used | Minimum | Maximum |
| char | 1 | −128 | 127 |
| unsigned char | 1 | 0 | 255 |
| short int | 2 | −32768 | 32767 |
| unsigned short int | 2 | 0 | 65535 |
| long int | 4 | ≈ −2 billion | ≈ 2 billion |
| unsigned long int | 4 | 0 | ≈ 4 billion |
| float
(6 significant digits) |
4 | ± 1.2 E −38 | ± 3.4 E +38 |
| double
(15 significant digits) |
8 | ± 2.3 E −308 | ± 1.7 E +308 |
Figure 3.1, numeric types and ranges
C also offers support for arrays and compound data types, and we will explore these concepts in a subsequent section.
In C, it is imperative to declare variables before utilizing them; unlike in Python, where variables can be created on the fly. A declaration comprises the variable type, followed by the variable name, and optionally, an initial value. Multiple declarations are permissible. Below are a few examples:
1. “char x;” declares a signed 8-bit integer denoted as “x.”
2. “unsigned char y;” declares an unsigned 8-bit integer identified as “y.”
3. “short z, a;” declares two signed 16-bit integers named “z” and “a.”
4. “float b = 1.0;” declares a real number named “b” and assigns it an initial value of 1.0.
It’s noteworthy that each of these declarations concludes with a semicolon. In the C language, the semicolon signifies “The statement ends here.” This means that you have some flexibility (or leeway) when it comes to handling spaces. The following variations are all equivalent and valid:
– “float b = 1.0; float b=1.0;”
– “float b = 1.0 ;”
3.3 Functions
Functions adhere to the same naming conventions as variables. They all follow a uniform template, which typically takes the following form:

You can conceptualize a function in the mathematical context, where it takes certain input value(s) and provides an output value in return. For instance, consider the sine function on your calculator: you input an angle, and it produces an output value. In the realm of C programming, functions can accept multiple arguments, not necessarily just one, and they may even function without any arguments at all. Additionally, C functions have the option to return a value, although it’s not mandatory. The actual operations performed by the function are defined within the pair of opening and closing braces, {}.
For instance, a function that receives two integers, “x” and “y,” as arguments and returns a floating-point value would be structured somewhat like this:
float my_function( int x, int y )
{
//…appropriate statements here…
}
When a function doesn’t require any input values and doesn’t return any values, it is denoted by the keyword “void.” In such a case, the function signature appears as:
void other_function( void )
{
//…appropriate statements here…
}
Initially, this might seem like meticulous work, but the explicit listing of data types serves a valuable purpose due to C’s feature known as type checking. In essence, type checking ensures that if you attempt to provide a function with the wrong type of variable or an incorrect number of variables, the compiler will issue a warning to alert you about the mistake. For instance, if you attempt to pass two floats or three integers to “my_function()” as shown above, the compiler will raise an objection, sparing you from potential issues during testing.
In C, every program must have a starting point, and program execution commences with a function named “main.” This function need not be the first one written or listed in your code, but it is mandatory for all programs to include a “main” function. Below is our initial program, presented in Figure 3.2.
/* Our first program */ void main( void )
{
float x = 2.0; float y = 3.0; float z;
z = x*y/(x+y);
}
Source: Embedded Controllers Using C and Arduino / 2E
- Why is C preferred over C++ for embedded systems?
C is preferred because C++ adds advanced features that create overhead which embedded applications typically cannot afford. - What hardware is required to start this course?
You need an Arduino Uno board, a USB host cable, and optionally a small wall-mounted power adapter. - How does C differ from Python regarding execution?
C is a compiled language producing efficient code, whereas Python is primarily interpreted and executes line by line. - Can I use a C++ book for learning C?
No, you must ensure the book focuses on C rather than C++ when selecting a text. - What is the role of a stack in C memory organization?
The stack provides temporary storage for variables used for limited durations within functions. - Do arrays have specific memory requirements in C?
Yes, arrays must be contiguous in memory and cannot be scattered across different locations. - Is a main function mandatory in every C program?
Yes, every C program must include a starting point function named main. - What happens if variable types do not match function arguments?
The compiler performs type checking and will issue a warning if the wrong type or number of variables is passed.