Summary of VOICE RECOGNITION SECURITY SYSTEM USING ATEGA32
This article details a real-time speech recognition security system built on an ATmega32 microcontroller. The project eliminates the need for external memory by processing samples directly via assembly-based bandpass filters and correlation analysis. Key features include training procedures to improve accuracy and an LCD interface for user feedback. The system operates at 4000 samples/second, utilizing specific digital filters to analyze voiceprints for password verification.
Parts used in the Voice Recognition Security System:
- ATmega32 Microcontroller
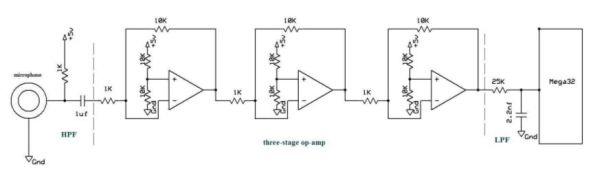
- Microphone Circuit
- Analog-to-Digital Converter (ADC)
- Digital Filters (Chebychev II implementation)
- LCD Display
- STK500 Development Board
When we think of programmable speech recognition, we think of calling FedEx customer service call center with automated voice recognition response systems. We also think of PC-based speech recognition Dragon NaturallySpeaking. Now we took that a step further. We are talking about speech recognition in a tiny Mega32 microcontroller. We are talking about real-time speech processing which means there is no need to store the samples in an external memory at all. This was made possible by implementing bandpass filters in assembly language with fixed-point format onto the microcontroller. In this filter design, not only the output of the filter is calculated, but its square and accumulation also obtained. Thus much time is saved so that each speech sample can be processed to get its frequency spectrum before next new sample comes. In addition, the analysis of the voice is made using correlation and regression method to compare the voiceprint of different words. These techniques provide stronger ability to recognize the same word. Training procedure is also used to reduce the random changes due to one word is spoken different times. The training procedure can get the more accurate frequency spectrum for one word. The experimental results demonstrate high accuracy for this real-time speech recognition system.

Introduction
Description of Project
The function of this speech recognition security system is to have a system that will only unlock upon recognizing a voice password spoken by the administrator or password holder.
Summary
Firstly, we looked at the speech recognition algorithm to understand the implementation. We then prepared the microphone circuit, and then proceeded to start sampling and generate the digital data for the speech. Once we have the data, we started writing the code based on Tor’s speech recognition algorithm. We also wrote the digital filters in assembly code to save the number of cycles necessary for the sampling rate of the speech, which is at 4K/second. Afterwards, we analyzed the output of the filters to recognize which word was spoken. Finally, we added an LCD for better user interface to signal if the password spoken is correct or not.
High Level Design
Rationale and Sources of Project Idea
We are inspired by the lab 3 where we did a ‘Security system’. We would like to add on to that using a speech recognition feature. This eliminates the need to type in a security code. Instead, you just have to speak a password to unlock the system. We are also interested in exploring and implementing the speech recognition algorithm and DSP.
Background Math
What we need to know in this project is how to calculate the frequency to sample speech based on the Nyquist Rate Theorem. Secondly, we also need to know how to calculate filter cutoff frequency to build the high and low pass RC filter for human speech. Thirdly, we need to know how to calculate the gain of differential op-amp. We had to learn about Chebychev filters to determine the cutoff frequencies to build the digital filters for human voice. As for the analysis part of the speech, we need to know how to calculate euclidean, correlation and simple linear regression. Lastly, we need to know how the Fourier Transform works, because we need to understand and analyze the outputs of the digital filters.
Logical Structure
The structure is very simple. The microphone circuit goes to the ADC of the MCU. The digitized sampling of the word is passed through the digital filters (flash programmed onto the MCU). The analysis is done on the MCU as well. Once that is done, the LCD which is connected to the MCU displays if the word spoken matches the password or not.
Hardware/Software Tradeoffs
The software tradeoff in this project is between the number of filters we can implement and the maximum number of cycles we have to adhere to. The more filters there are, the more accurate the speech recognition will be. However,because each filter takes about 320 cycles and we could not implement more than 2000 cycles, we had to trade off the accuracy of the system and limit the number of filters to 7.
Standards applicable to design
There should be no standards that would affect this project.
Program/Hardware Design
Program Design
Because there is not enough memory (SRAM) on the STK500, we have to deal with speech analysis during each sample interval. The key point of this project is to how to design filters and how to implement them. There are two major difficulties we need to solve: First reduce the running time of each filter in order to get all the finger prints before next new sample comes. So we have to use fixed-point algorithm. Secondly, set the reasonable cutoff rate for each filter and number of stages of the filters.
- Speech spectrum analysisGenerally the human speech spectrum is less than 4000Hz. According to Nyquist theory, the minimum sampling rate for speech should be 8000samples/second. Due to our system is voice-controlled safety system; it is very helpful to analyze the speaker’s voice before our actual design.Our design is based on the recorder program installed in Windows XP and FFT function in Matlab. After we speak one word, the recorder program will store the word in a .wav file. Notice this file is sampled at 16000 samples/second, 16bit/sample, so we need to convert it into 8000samples/second, 8bits/sample. The whole analysis procedure is as the following figure.
- From the above analysis result, we select the sampling rate in our system is 4000sample/second, 8bits/sample. The cutoff frequency for LPF and HPT is 50Hz, 1500Hz respectively. In order to get the accurate fingerprint of the code, we use seven filters, their working range are:
- LPF: [0-50Hz]
- BPF_1: [50-350Hz]
- BPF_2: [350-500Hz]
- BPF_3: [500-750Hz]
- BPF_4: [750-1000Hz]
- BPF_5: [1000-1500Hz]
- HPF: [> 1500Hz]
- Fs=4000; %Hz
- Fnaq=Fs/2; % Nyquist
- [B0, A0]=cheby2 (2, 20, f0); % LPF
- [B6, A6]=cheby2 (2,20, f6, ‘high’); % HPF
- [B1, A1]=cheby2 (2, 20, [f0 f1]); % BPF
For LPF and HPF, we just use second order filter. For BPF filters, we use fourth-order filter. In implementation, the fourth-order filter actually is cascaded by two second-order filters. The coefficients of these two second-order filters are obtained by the following Matlab command:
[sos1, g1]=ft2sos (B1, A1,’up’, ‘inf’);
For the LPF and HPF filter, we take Bruce’s sample code as a reference. However, we made a little change. The fingerprint of the speech is the accumulation of the square of the output of each filter. So we combine the calculation the square and accumulation in one filter function. For the fourth-order BPF, we duplicate the second-order filter but using different coefficients. After finishing our code, we tested the filter based on two cases.
First, using an Impulse sequence to test it and compare the result with Matlab. This case is to test whether our filter correction is correct. Here we used sample impulse sequence xn=[16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ]
Second, using source generator to generate different frequency sine waves and send them to the filter. The results are also comparing with Matlab’s result. This case is to test whether our filter’s frequency setup is correctly or not. The following figure is our test result of the second case.
-
From the above plots, the output from BPF (350-500Hz) has a maximum value, which exactly matches the testing sine wave (355Hz).We also use 800Hz sine wave to test our filter arrays. Figure.5 shows the result which also proves our filter design is correct.
For more detail: Extended Abstract Using Atmega32
- How does the system unlock?
The system unlocks only upon recognizing a specific voice password spoken by the administrator. - Can the system process speech without external memory?
Yes, real-time processing is achieved by implementing bandpass filters in assembly language directly on the microcontroller. - What sampling rate was selected for the design?
The system uses a sampling rate of 4000 samples per second with 8-bit resolution. - Why were the number of filters limited to seven?
The limit was imposed due to cycle constraints, as each filter requires about 320 cycles and the total must stay under 2000 cycles. - Does the project use fixed-point algorithms?
Yes, fixed-point format is used to reduce running time and ensure fingerprints are calculated before the next sample arrives. - What method is used to compare voiceprints?
The system uses correlation and regression methods to analyze and compare the frequency spectrum of spoken words. - How does the training procedure help?
Training reduces random changes caused by variations in how a word is spoken, resulting in a more accurate frequency spectrum. - Which filter types are included in the design?
The design includes a Low Pass Filter, High Pass Filter, and five Band Pass Filters covering specific frequency ranges.