SingLock is a pitch-based security system based on ATMEL MEGA1284P microcontroller featuring two password protection stages: one based on a 4-digit numeric personal identification number inputted via the keypad and another based on two pitches inputted via the microphone.
Most security systems we find today are keypad and/or keyboard-based. Speech, rather than button-pressing and/or typing, is however the main means of communications for most people. It is therefore intuitive to have speech as the basis of encryption when considering human usability factors and ease-of-access. Consequently, we developed SingLock. SingLock’s password detection scheme maintains a user’s voice signature so that an eavesdropper who knows both the user’s personal identification number and the passkey pitch cannot easily unlock the system. SingLock’s sound-based security system also does not leave residues, such as heat signatures on a keypad after a button press, that may make the system vulnerable to penetration by outsiders. SingLock hence is relatively more secure than average keypad and/or keyboard-based systems. The minimalist design and the keypad, microphone, and liquid crystal display (LCD) user interface makes the system easy to use for a wide range of users.

High Level Design
Rationale
Microcontrollers are used widely in contemporary security systems. For our final project, we wanted to build our own microcontroller-based security system with an added human speech-based encryption and decryption scheme by combining our shared interests in both security and signal processing. Given the limited computational power of the ATMEL MEGA1284P microcontroller, we simplified the sound-based component of our system from speech and voice recognition to pitch recognition, based on frequency peaks of the input sound.
Logical Structure
SingLock is comprised of three main components. The first component is the keypad and LCD screen that serves as the main user interface of the system. Using the keypad, the user must follow the instructions provided on the LCD screen in order to lock and unlock the system correctly. The second component is the analog audio input signal processing. We amplify and band-pass filter the microphone input signal in order to remove noise using a single op amp circuit. This preprocessed analog audio input signal is sampled by the Analog-to-Digital Converter (ADC) of the microcontroller for postprocessing. Both the LCD and the set of two LEDs serve as indicators of the system’s lock state. Initially, both the red and green LEDs are lit. When the system is locked correctly, only the red LED is lit. When the system is successfully unlocked, only the green LED is lit. The figure below shows the high-level logical structure of the SingLock system without the keypad and LCD screen.
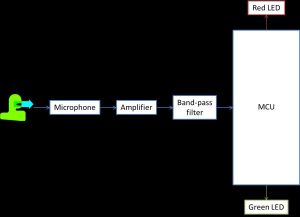
The user’s sung pitch is recorded by the microphone. The analog acoustic input signal is then amplified and filtered to remove ambient noise. The amplified and filtered signal is then sampled into a digital signal by the ADC of the microcontroller. We then take the FFT of the sampled signal and match peaks to the stored peaks in the passkey in the frequency domain. If a predefined number of stored peaks in the passkey are found in the stored frequency peaks of the microphone input signal, the system unlocks. Otherwise, it remains locked.
SingLock is built on a few fundamental concepts in signal processing, namely sampling theory and frequency domain analysis of audio signals. Sampling is carried out so that the system operates at a reasonable range of frequencies. Peak-matching calculations performed at every attempt to unlock the system is carried out using the Fast Fourier Transform (FFT) algorithm. We review these signal processing fundamentals in the next section.
Mathematical Background
The pitch-based security system relies on matching a predefined set of magnitude peaks in the frequency domain to the frequency peaks of the sampled analog microphone input sound. We sampled the analog microphone input sound at 4kHz, which provided us with up to 2kHz in usable frequency range without aliasing, according to the Shannon-Nyquist Sampling Theorem. An average person can generate acoustic sounds that range from about 100Hz up to about 1200Hz in frequency. Therefore, we selected a sampling rate of 4kHz, which provided us with a reasonable upper frequency limit of 2kHz for the input sound.
Frequency peaks were calculated by taking the Fourier transform of the sampled digital signal and calculating the magnitudes of the Fourier transform coefficients. The Fourier transform of a signal returns a set of coefficients that collectively represent the signal’s energy distribution across a range of frequencies. Because our system is digital, we carry out the Fourier transform operation for discrete signals, known as the Discrete Fourier Transform (DFT). The DFT takes an N-point signal and computes the Fourier transform, returning an array containing N coefficients with each bin representing a frequency range and each coefficient in a bin representing the energy present at the corresponding frequency range. The N-point DFT is defined as follows:
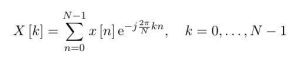
For exclusively real-valued signals, the corresponding frequency domain representation is symmetric about the (N/2)th coefficient. Because the sampled microphone input signal is strictly real-valued, we only calculate the magnitudes of the first (N/2) DFT coefficients, with the lowest frequency bin containing the zero frequency and the highest frequency bin containing the upper frequency limit set by the sampling frequency.
We implement the Fast Fourier Transform (FFT) algorithm, which is essentially a fast method for computing the DFT to obtain the frequency domain representation of the sampled microphone input signal. The FFT algorithm recursively divides the N-point signal and computes the DFT. This divide and conquer algorithm reduces the asymptotic complexity of the N-point DFT from O(N2) to O(Nlog2(N)), where N is a power of 2.
Hardware/Software Tradeoffs
Our hardware design follows a minimalist approach. A single op amp is used to perform both amplification and band-pass filtering. High-pass filtering is carried out by a capacitor. A component consisting of a resistor and a capacitor in series performs low-pass filtering. There are better, but more costly ways to amplify and band-pass filter the microphone input signal. We decided to use this simple amplification and band-pass filter system to minimize hardware footprint. The simple hardware system did not completely filter out DC biases and noise in practice. We accounted for this deficiency in hardware with software implementation. By comparing multiple frequency peaks in software, there was no need to eliminate DC biases and noise completely. We could have implemented a more sophisticated amplification and filter system in hardware, but the hardware components would have taken up more area on the limited breadboard space and would also have drawn more power. Our software implementation adequately compensated for the aforementioned hardware limitations.
Applicable Standards
The only applicable standards that our project needs to conform to is that it takes 9V DC from the power adapter. There are no other standards applicable to this project to the best of our knowledge.
Existing Patents, Copyrights, and Trademarks
We could not find existing patents and copyrighted or trademarked items relevant to our project. To the best of our knowledge, our project does not infringe patent laws and does not make use of copyrighted or trademarked materials.
Hardware Design
The detailed circuit schematic diagram of the microphone user interface system is shown in Appendix B so that anyone else can build our hardware component based on what is written in this section. A single capacitor across the microphone serves as an elementary high-pass filter. The voltage divider with two 100k resistors was used to provide a DC bias of 2.5V for the ADC, which has values ranging from 0 to 255. With the ADC reference voltage set to 5V, corresponding to the ADC value of 255, this DC bias set the zero amplitude point to the ADC value of 128, yielding maximal swing for the microphone input signal. A single LM358 op amp was used to amplify and low-pass filter the microphone input signal. We implemented a non-inverting amplifier, with gain set to 1+(1MΩ/1kΩ) = 1,001. We found that a gain of about 20 would have been sufficient in theory. Nevertheless, in practice, we found that the gain of 20 was not sufficient to suppress the harmful interference from the noisy environment in which we worked. Through trial and error, we found that a gain of about 1,000 was sufficient in practice. We also added a simple low-pass filter to the non-inverting amplifier using a resistor and a capacitor in series. The low-pass filter cutoff frequency was set to 1/(1kΩ*100nF) = 10kHz. The amplified and band-pass filtered output of this circuitry was inputted to the A0 channel of the microcontroller’s ADC for postprocessing.

Software
The entire software of SingLock system consists of multiple Finite State Machines (FSMs), in addition to the FFT and Peak Detection and Matching Code. There are three FSMs in total: System FSM, Keypad Debounce FSM, and Pitch Detection FSM. They are described in detail below.
Finite State Machines
System Finite State Machine
This FSM is the main building block of this machine. In the code, the state of this FSM is indicated as the globalState. This is the most complex FSM in the SingLock system. The state transition diagram of this FSM is included below.
![]()
Right after the system is turned on or reset, the System FSM will start on the INITIALIZE state. This state tells the user that the system is active and the user should press button A to proceed in configuring the system for use. After button A is pressed, the FSM will transition to state INITPSWD, in which the user should type in a 4-digit password. After the password has been typed, the user should then press button A to proceed to the next state, INITPITCH. This state regulates the pitch detection for password. It prompts the user to start holding a pitch and press the A button to input the first pitch. It then asks the user to hold the second pitch and press the A button again. If the user is satisfied with his/her pitches, he/she can press button A to move to the next state, LOCKED, in which the system is fully configured and locked. If the user wants to repeat his/her pitches, he/she can press button B to re-input his/her two pitches.
In the state LOCKED, the red LED is lighted, indicating that the system is locked and the LCD display also indicates that the system is locked and the user should press button A to start the unlock sequence. When button A is pressed, the FSM transitions to state ENTERPSWD, in which the user needs to type in the correct password and then press A to proceed to the next state, ENTERPITCH. In this state, it does the same procedure as in INITPITCH, but this time, the pitches are used to unlock the system. If the user is satisfied with his/her pitches, he/she can press button A to try and unlock the system. If the user wants to repeat his/her pitches, he/she can press button B to re-input his/her two pitches. If button A is pressed, the system checks both the typed numeric password as well as the pitches. If any of these two are incorrect, the system goes back to state LOCKED and the entire unlock sequence needs to be retried. If there are three or more consecutive incorrect unlock sequences, the system transitions to state JAILED, in which the user is jailed for 10 seconds before he/she can begin another unlock sequence.

If the unlock is successful (both the numeric password and the pitch password match), the system goes into the UNLOCKED state. In this state, the green LED is turned on indicating that the system is unlocked and the LCD display indicates that the system is unlocked and the user should press A to re-lock or press B to change the password. If button A is pressed, the system transitions into state LOCKED. If button B is pressed, the system transitions into INITPSWD state.
Keypad and Debounce Finite State Machine
The keypad serves as the main user input module for the system. The physical keypad used is a 4-by-4 keypad, with the layout as follows:
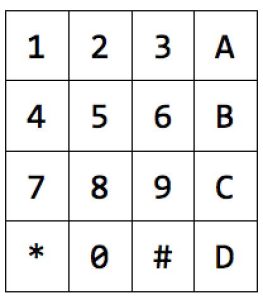
There are 9 output pins, and the 9th pin is a no-connect. The keypad works as follows: there are 4 vertical wires and 4 horizontal wires. A button press connects the vertical and horizontal wires corresponding to that button. Hence, each pin corresponds to either one row or one column. By noticing which column wire and row wire are connected, we can know the button that is pressed. The system scans the keypad to register a button press (detailed implementation of the keypad scanning code is in the documentation section), as well as implements a debouncing Finite State Machine (FSM) to ensure that the keypad is properly debounced.
The keypad scanner works as follows: it outputs a logic low to the 4 horizontal wires while enabling the internal pull-up resistors on the 4 pins connected to the 4 vertical wires. Then it takes in the value read by the 4 pins connected to the 4 vertical wires. If a button is pressed, then one of the vertical values should read low as the horizontal wire (which is pulled low) and the vertical wire corresponding to that button are connected. This process is repeated, but now the system outputs a logic low to the 4 vertical wires while enabling the internal pull-up resistors on the 4 pins connected to the 4 horizontal wires. It takes in the value read by the 4 pins connected to the 4 horizontal wires. If a button is pressed, then the value of one of the horizontal wires should read low as the vertical wire (which is pulled low) and the horizontal wire corresponding to that button are connected. This value is OR-ed with the value obtained before. Hence, through this process, we can obtain the specific button press.
The keypad debounce FSM is illustrated below:
![]()
To prevent erroneous button press detection, the system checks every 50ms if a button is pressed. If there is no button press, the keypad scanner assigns a value of zero to the variable butnum. If a valid button is pressed, butnum will contain a non-zero value. The first state in the debouncing FSM is the NOPUSH state. This is the state in which no button is pressed. It stays in this state if butnum == 0 every single time the keypad scanner is called. If butnum != 0 (a button is pressed), the state machine transitions to the MAYBEPUSH state. This state is the ‘guard’ state against erroneous button press. When the next keypad scanner is called, if the button is no longer pressed, we know that this is an erroneous press and the system transitions back to the NOPUSH state. However, if the button remains pressed, we know that this is a valid button press, and the state machine transitions to the DETECTTERM state. This state determines the action necessary based on the current System FSM’s state and the type of button pressed, and moves to the PUSHED state.
The PUSHED state is the state in which a button is definitely being pushed. It stays here until the button is released (butnum == 0), and then it transitions to the MAYBENOPUSH state. This state is the ‘guard’ state against erroneous button release. When the next keypad scanner is called, if butnum != 0, we know that there is an erroneous detection of button release, and we transition back to the PUSHED state. Otherwise, we have detected a legitimate button release and the debouncing FSM transitions to the NOPUSH state. It is worth noting that the DETECTTERM state only gets executed once per button press, as it is a ‘transitional’ state from MAYBEPUSH to PUSHED. This guarantees that any change resulted from the current button press is only executed once.
Pitch Detection FSM
The pitch detection FSM is only activated when the System FSM is in INITPITCH or ENTERPITCH states. This FSM regulates the ADC sampling and FFT processing in the MCU. When System FSM first enters INITPITCH or ENTERPITCH, the pitch detection FSM is in PREP state, in which it prompts the user to hold a pitch and press button A. It then transitions to PITCH0 in which it samples the analog signal from PORT A0 and does the FFT. It then prompts the user to hold another pitch and press button A. The FSM transitions to PITCH1, in which it samples the second analog signal from PORT A0 and does the FFT. It then automatically transitions to state DONE after FFT and peak detection is complete. If button A or B is pressed, it goes back to state PREP to get the system ready for another cycle of pitch detection depending on the System FSM (globalState).
![]()
Analog-to-Digital Converter (ADC) Sampling and Fast Fourier Transform (FFT)
In order to achieve a sampling rate of 4 kHz, we sampled the preprocessed analog signal in a timer 1 interrupt service routine (ISR) that fired every 250us. Because we set the microcontroller CPU to operate at its maximum clock frequency of 16 MHz, firing the ISR every 4000 machine cycles yielded a sampling interval of 250us, which corresponds to a sampling rate of 4 kHz. We stored the sampled signal in the array with 128 elements in size that is reserved for the real part of the FFT coefficients, fr.
We integrated Bruce Land’s implementation of the forward-only FFT algorithm for fixed-point signals (FFTfixGCC644_macro.c) in our code. This implementation performs the FFT on two arrays: one reserved for the real part of the FFT coefficients and another reserved for the imaginary part, fi, in place. Before the FFT operation, fr holds the sampled microphone input signal and fi is nulled to zero. After the FFT operation, fr and fi contain the real and imaginary parts of the transform coefficients, respectively.
Because the sampled microphone input signal is strictly real-valued, the signal’s frequency domain representation is symmetric about the 64th entry. Therefore, we only calculate the magnitudes of the first 64 transform coefficients. Because we sampled at 4 kHz, the maximum frequency that can be represented is 2 kHz. Therefore, the frequency resolution of our system is 2 kHz/64 = 31.25 Hz. This frequency resolution range yields a reasonable level of tolerance for error in pitch frequency so that people without the absolute pitch ability are still able to use the system without much difficulty.
Peak Detection and Matching
The system unlocks if the two recorded pitches in an attempt matches the two pitches stored in the passkey. We store 10 highest frequency peaks (peaks with the greatest magnitudes, and thus energies) for each pitch for both the attempted pitch and the recorded pitch in the passkey. Of the 10 stored peaks for the pitch in the passkey, we only look for the 3 highest peaks in the passkey pitch among the 10 stored peaks for the attempted pitch. If all 3 highest peaks in the passkey pitch are present in the 10 stored peaks in the attempted pitch, we have a pitch match. If we have a match for every pitch in the passkey, the system unlocks. There are multiple ways to determine whether or not we have a match. Developing this method of match detection, which has been optimized for human voice via trial and error, was quite tricky, but the method proved to be very robust and quite reliable.
The number of peaks stored and the number of peaks compared were optimized for human voice via trial and error. These two parameters collectively determine how strict the system is with regard to pitch detection and matching, and thus can be tuned according to the users’ specific needs.
We implemented the merge sort algorithm to rank the frequency bins with respect to the transform coefficient magnitudes in ascending order. Our merge sort algorithm was modified from the code published here.
Similar to the FFT algorithm, merge sort has a worst-case scenario asymptotic complexity of O(Nlog2(N)) with a recursive divide and conquer algorithm. An easily implementable sorting algorithm would have had a complexity of O(N2), requiring 4906 operations to compare 64 transform coefficients. Using merge sort, only 384 operations are needed at worst, saving more than an order of magnitude number of operations to perform the same sorting task.
Important Functions
int main(void)
The main function first calls the method initialize() and enters a while(1) loop. This loop continuously calls keyDebounce() to detect any key press, outputs the correct LED (RED if the system is locked, GREEN if the system is unlocked, and BOTH if the system is still being configured). This main loop also handles the JAILED state and decrements a jail counter, which is the amount of time left before an unlock attempt can be retried on the system.
TIMER1 Compare A ISR
This ISR samples the ADC port (A0) input at a rate of 4 kHz (fires once every 250us) and it enters from sleep mode ensured by timer1 compare B ISR to guarantee correct time synchronization. The sampling only happens when the flag is set to 1 and it sets the flag back to 0 when the entire set of samples has been obtained.
TIMER1 Compare B ISR
This ISR puts the MCU to sleep right before the Timer 1 Compare A ISR goes off. It has an ISR_NAKED argument so that the register values are not stored into the stack to enable the MCU to enter and exit the interrupt faster. It first enables the global interrupt flag so that the Timer 1 Compare A ISR can wake the CPU from sleep. It then enters the sleep_cpu() routine to sleep the CPU, and then returns from interrupt.
TIMER2 Compare ISR
This ISR fires once every millisecond and functions to decrement the counters for LED, keypad, and jail counter.
void initialize(void)
This method initializes all the PORTs and other registers for proper system functionalities. First, it sets all LED-connected PORTs to outputs. It then sets up timer 1 as follows: enable clear-on-match feature, sets clock divider to be 1, and enables OC1A and OC1B interrupts. The method then initializes the LCD and sets up the ADC. It then sets up timer 2 for 1 millisecond timebase and initializes the task timers (for LED and keypad). Following that, it sets the initial state of the FSMs, and initializes the pitch password and pitch password challenge arrays. Subsequently, it prints that the system is activated on the LCD and sets up the sine table required for the FFT. Lastly, it enables global interrupts and enables sleep mode.
void keyScanner(void)
The keyScanner() method scans the keypad for a button press. It begins by getting the lower nibble of the keypad byte while activating the internal pull-up of the lower nibble and at the same time exerting a logic low signal to the upper nibble of the keypad byte. After a 5 microseconds delay, the resulting value from the keypad is saved into the variable key. The method continues by getting the upper nibble of the keypad byte while activating the internal pull-up of the upper nibble and at the same time exerting a logic low signal to the lower nibble of the keypad byte. After a 5 microseconds delay, the resulting value from the keypad is OR-ed to the current key value. The method then tries to find the matching keycode in keytbl. If the matching keycode is found, then the method changes the value of butnum to the decoded value. If no key (or multiple keys) is pressed, then butnum gets the value of zero.
void keyDebounce(void)
This method maintains the main Finite State Machine for debouncing the keypad as well as the system FSM. It first checks if timeKeypad is zero. If it is not, the method simply returns. If it is, it proceeds to call the keyScanner() method to get the current button pressed (if any). Afterwards, the code enters a large switch-case block that implements the FSM outputs and transitions.
The first case is a NOPUSH case. If butnum != 0, the keypad debouncing FSM transitions into MAYBEPUSH. Otherwise, the debouncing FSM stays in NOPUSH. In MAYBEPUSH state, if butnum != 0, the keypad FSM transitions into DETECTTERM. Otherwise, the keypad FSM transitions into NOPUSH.
In DETECTTERM state, there are multiple actions depending on the current button pressed and the current system FSM and pitch detection FSM. The state transitions can be seen in the current system FSM state diagram as shown before. When the pitch detection FSM indicates that the state is supposed to record a pitch, the ADC sampling flag is set to 1.
In state PUSHED, the keypad debouncing FSM will remain in this state as long as the button is pressed. Otherwise, the FSM will transition into MAYBENOPUSH state. In MAYBENOPUSH state, if butnum == 0, the keypad FSM will transition into the NOPUSH state. Otherwise, if a button is pressed, the keypad FSM will transition into the PUSHED state.
void printScreen(void)
This method displays the appropriate string on the LCD. IT always move the cursor to position (0,0) after exit.
void pitchDetect(void)
This method is the main routine for all postprocessing and analysis of the recorded sound. Whenever the buffer storing the sampled microphone input signal, fr, is filled, the script prepares for the FFT operation by setting all elements of the imaginary component of the signal to 0, enforcing the constraint that the sampled microphone input signal is purely real-valued.
We then perform the FFT, which returns the real and imaginary parts of the transform coefficients as fr and fi, replacing the values of the arrays in place. We then calculate the magnitudes of the transform coefficients, sort them in ascending order using the merge sort algorithm, and store the 10 highest magnitude peaks in the frequency domain.
void mergeSort(int sorted[], int indices[], int len)
This method, in conjunction with the method merge described below, performs the sorting task via the recursive merge sort algorithm. The transform coefficients to be sorted are stored in the array sorted and the array indices is initialized in incrementing order from 0 to the number of magnitudes to be sorted, len = 64, before the mergeSort call. After the call, the sorted magnitude values are stored in the same array sorted and the indices corresponding to the sorted magnitudes are stored in the same array indices. Therefore, mergeSort sorts the input arrays effectively in place.
void merge(int sorted[], int indices[], int mid, int len)
This method compares the numbers to be sorted and actually performs the sorting task.
void tryUnlock(void)
This method compares the initialized password with the password challenge from the user who tries to unlock the device. It first checks if the numeric passwords are consistent, then checks if the pitches match using the pitchDetect function. If both matches, then the system unlocks and the password error count is reset to 0. If a mismatch is found, the function increments the password error count, and if the error count exceeds 2, the system enters the JAILED state. Otherwise, the system remains in LOCKED state.
int matchPitch(void)
This method returns 1 if the two attempted pitches match the two pitches stored in the passkey, and 0 otherwise. If this method returns 1, the system unlocks. Otherwise, it remains locked. We have 10 highest magnitude peaks stored for each pitch both attempted and stored in the passkey. Out of the 10 peaks for one pitch in the passkey, we only search if the 3 highest peaks among the 10 are present in the set of the 10 stored peaks for the corresponding attempted pitch. If all 3 peaks are present, then we have a match for that attempted pitch. If we have a match for every pitch in the passkey, the method returns 1, unlocking the system. Otherwise, it returns 0.

void FFTfix(int fr[], int fi[], int m)
This method, from Bruce Land, performs the forward-only FFT operation for array data of size that is a power of 2. This method uses the fast fixed point multiply assembly macro for speed. The arrays fr and fi are respectively the real and imaginary components of the data before the operation is performed. After the operation is carried out, the real and imaginary parts of the computed transform coefficients are stored in fr and fi, respectively.
Results
For the result, we evaluated the success of our project based on the following criteria:
1. Ease of use
2. Accuracy of pitch detection
3. Responsiveness of the system
4. Build quality and safety
For the first criterion, we ensured that the SingLock system is easy to use by using an LCD to display the user prompt. The instructions on the LCD walks the user step-by-step in both configuring the system and in using it.
For the second criterion, we measured it by two methods: using computer-generated pitches from our cellphones and using human voices from both Alvin and I, as well as Bruce and other people as well. If the pitch detection is accurate, the system should be able to be locked and unlocked using the same pitches. Moreover, the system must not be able to be unlocked using a different pitch. Our system is proved to have 100% accuracy for the computer-generated pitches from our cellphones using frequencies from 330 Hz to 990 Hz with a 110 Hz increment. This is the best-case scenario as the pitches played during the configuration and during unlock attempt are perfectly consistent with each other. The table for the results of this experiment is as follows:
| Unlocks? | Unlock Frequency (Hz) | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
|---|---|---|---|---|---|---|---|---|
| Configuration Frequency (Hz) | ||||||||
| 300 | YES | NO | NO | NO | NO | NO | NO | |
| 400 | NO | YES | NO | NO | NO | NO | NO | |
| 500 | NO | NO | YES | NO | NO | NO | NO | |
| 600 | NO | NO | NO | YES | NO | NO | NO | |
| 700 | NO | NO | NO | NO | YES | NO | NO | |
| 800 | NO | NO | NO | NO | NO | YES | NO | |
| 900 | NO | NO | NO | NO | NO | NO | YES |
Hence, we know that for computer-generated frequencies that differ by 110 Hz every single time, the device works 100% of the time.
Hence, we then tried to understand what the minimum limit of the frequencies that the device can take before it gives false positives (frequencies actually differ, but the device thinks that the frequencies are the same). The result is as follows:
| Unlocks? | Unlock Frequency (Hz) | 450 | 460 | 480 | 500 | 520 | 540 | 550 |
|---|---|---|---|---|---|---|---|---|
| Configuration Frequency (Hz) | ||||||||
| 500 | NO | NO | YES | YES | YES | NO | NO |
Hence, we determine that the device is able to detect frequencies accurately up to around 40 Hz resolution. This is close enough to the bin resolution that our device has: 2000/64 = 31.25 Hz.
For real human voices, the result is as follows:
| Alvin Wijaya | System unlocked 90% of the time with the same attempted pitch between configuration and unlock. When the attempted pitches were made to differ, the system successfully remained locked 100% of the time. When attempts were made to reproduce Sang Min’s pitches, the system successfully remained locked 80% of the time. |
|---|---|
| Sang Min Han | System unlocked 100% of the time with the same attempted pitch between configuration and unlock. When the attempted pitches were made to differ, the system successfully remained locked 100% of the time. When attempts were made to reproduce Alvin’s pitches, the system successfully remained locked 70% of the time. |
| Bruce Land | Out of two attempts, the system unlocked 100% of the time with the same attempted pitches between configuration and unlock. |
All of the real human voice attempts were done in a digital instruments laboratory at Cornell University. Hence it simulated real-world noise, such as CPU sound, people talking in the background, fan noise, and other background noises.
These results gave us confidence that the system is not only functional, it has an inherent advantage in distinguishing similar pitches from two different people due to the different shapes of throats of different people. Alvin’s attempts to replicate Sang Min’s pitches only worked 20% of the time, and Sang Min’s attempts to replicate Alvin’s pitches only worked 30% of the time. We believed that with further refinements, we could lower these numbers substantially.
We found that the ability to re-input pitches is essential to the overall usability of the whole system as this gives the user confidence that he/she has input the correct pitch and any pitch that seems unsatisfactory to the user can be changed immediately before the system gets locked or before the system tries to unlock. Moreover, we also found that interference from other people or device in the vicinity generally do not affect the accuracy of pitch detection. We did our trials in the digital instruments laboratory at Cornell University where there are many active computers, and it did not affect our results. However, a loud voice (from a dropped object or from a person shouting) did affect the accuracy of the device. Nevertheless, the user can always re-input his/her pitches if he/she detects significant noise in the environment when he/she tries to input the pitches. Hence, the effect of the device’s vulnerability to loud noise in the environment is mitigated.
For the third criterion, we measure how long each state transition takes. The only noticeable lag in the system occurs when the system first starts up as it builds the sine wave table required for the FFT. This takes in the region of 1.5 seconds. Nevertheless, since it only happens during start-up, it does not affect the overall usability of the device. Throughout the entire experience of using the device, there is no noticeable delay that affect the interactiveness of the device. The pitch detection takes less than 0.5 seconds each, ensuring a relatively fluid usage. Hence, we strongly believed that the system is usable and responsive for most people’s needs.
For the fourth criterion, we tried moving our device when a user is inputting his/her pitch. The result is still consistently good: unless the user touches the bottom of the microphone, the accuracy of the device is still perfect. When the user touches the bottom of the microphone, significant noise could be seen on the oscilloscope and thus affected the functionality of the device. We could have put an electrical tape at the bottom of the microphone to prevent similar occurrences in the future. We enforced safety in the design by ensuring that all wires have rubber insulation on them. This minimizes the danger of electrocution or short-circuit.
Conclusion
Evaluation
Overall, the SingLock system works as expected. It is able to distinguish between different pitches, even between people who tried the same pitch. The user interface is relatively responsive, logical, and helps to guide user to configure and use the system. Nevertheless, there are several possible improvements that we can think of if we have more time. One possibility is to use LCD and keyboard with backlighting so that the system can be used in dark environments. Another possibility is to use a different pitch detection algorithm that separates tall peaks and smaller peaks and classify them based on the overall heights instead of simply comparing the highest peaks. This would allow for a better pitch detection.
Intellectual Property Considerations
The entire hardware design of Sing Lock was done without referencing any other designs or the intellectual property of others. Most of the software for the project is also developed by the authors, but some codes are obtained using public GNU license. The first of such code is the LCD library (lcd_lib.c and lcd_lib.h), which is obtained from ECE 4760 class page, and is adapted from scienceprog.com using GNU public license. Moreover, the FFT calculation code is adopted from the code provided by Bruce Land and is available on the course web page. This code was originally written by Tom Roberts and improved by Malcolm Slaney. Bruce Land had the rights to use and modify this example code. Some of the code used are adapted from our own code in Lab 2 in ECE 4760 Fall 2014. Codes used to set up the microcontroller for the FFT operations and the code to calculate FFT magnitudes were modified from a source code from a past project titled “Audio Spectrum Analyer” by Alexander Wang and Bill Jo. Our implementation of the merge sort algorithm was modified from the source code provided here.
All diagrams used are made by us and all pictures taken are our property as well. We have conformed to the standards that SingLock is powered from a 9V DC voltage from the adapter. As far as we are aware of, there is no similar embedded systems work that use pitch-based detection for security system. However, there are indeed research work being done in using pitch-based detection algorithms for security system such as this one.
Nevertheless, we did not use the same algorithms as what have been proposed and we believe that our project is novel in the sense that it is simple enough to be implemented in a small, affordable, and simple embedded systems package. We did not sign any non-disclosure agreements (NDAs) relating to this project throughout the duration of this project. While we have not done a comprehensive search through all available patents related to our work, we believe that there may be a patent opportunity for SingLock.
Ethical Considerations
Throughout this project, we have closely followed the IEEE Code of Ethics. Consistent with code ethics bullet number seven that states “to seek, accept, and offer honest criticism of technical work, to acknowledge and correct errors, and to credit properly the contributions of others,” we discussed the project details with our TA and Bruce Land to obtain feedback and iterates on the project design, as well as disclosed all materials that we have adapted and borrowed from other entities. Such materials include the FFT code and the LCD code that we obtained from Cornell’s 4760 course website. We made it clear which part of the code that we have originally developed on our own and which part of the code are borrowed or adapted from others. Moreover, compliant with bullet number three, “to be honest and realistic in stating claims or estimates based on available data,” our results are obtained using real-life data and we never made any assumptions or claims without being substantiated. For results collection, we used both Alvin’s and Sang Min’s voices as well as asking other people such as Bruce Land to test it to provide greater objectivity to our result. Also, consistent with the first bullet about disclosing factors that may endanger the public or the environment, we have also disclosed the risk of using our product. The only possible injury risk from using this device is from electrocution from short-circuiting any power wires. However, as the power supply used have short-circuit protection and the wires are insulated, this risk is minimized. These bullet points are the primary ethical considerations that were involved in developing our project. Nevertheless, we have complied with all bullets in the IEEE Code of Ethics.
Legal Considerations
As far as we know, there are no legal considerations involved with our project.
Appendices
Appendix A. Source Code
- final_project.c (21 KB)
- final_project.h (5 KB)
- lcd_lib.c (9 KB)
- lcd_lib.h (5 KB)
Appendix B. Schematics
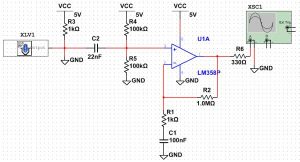
C. Cost
Our total cost for this project came out to be $30.50. The majority of this cost came from the Keypad, microcontroller, and LCD display. Our cost breakdown is listed below.
| Part | Source | Unit Price | Quantity | Total Price |
|---|---|---|---|---|
| ATMEL ATMega1284 | ECE 4760 Lab | $5.00 | 1 | $5.00 |
| Custom PC Board | ECE 4760 Lab | $4.00 | 1 | $4.00 |
| 0-20kHz Microphone (CMA-6542PF) | ECE 4760 Lab | $2.50 | 1 | $2.50 |
| Large Solder Board (6″) | ECE 4760 Lab | $2.50 | 1 | $2.50 |
| 4×4 Keypad | ECE 4760 Lab | $6.00 | 1 | $6.00 |
| LCD (16×4) | ECE 4760 Lab | $8.00 | 1 | $8.00 |
| Header Pins | ECE 4760 Lab | $0.05 | 50 | $2.50 |
| Capacitors, LEDs, resistors | ECE 4760 Lab | $0.00 | As used | $0.00 |
| Wires | ECE 4760 Lab | $0.00 | As used | $0.00 |
| LM358 Op-amp | ECE 4760 Lab | $0.00 | 1 | $0.00 |
| Total | $30.50 |
D. Division of Labor
| Alvin Wijaya | Sang Min Han | Both |
|---|---|---|
| Conceptualized and designed the FSMs required for the project | Conceptualized and designed the FFT and peak matching algorithm required for the project | Developed the high-level concept of the project |
| Implemented and tested the FSMs | Implemented the hardware required for the project on the breadboard, such as the microphone circuitry and the amplifier | Continuously tested the project, ensuring the best design parameters for voice use |
| Integrated the FFT code from Sang Min and the Finite State Machines into one functional system | Integrated FFT code from the course website into our project and tested it | Developed, finished, and polished the final project and project report |
| Finished soldering the components into a solder board for a more robust hardware | Started soldering the components into a solder board for a more robust hardware |
Source: SingLock